


بررسی تخصصی آلفاتک: ساخت کلاستر ۸ نودی با NVIDIA GB10؛ قدرت پردازشی عظیم با مصرف انرژی ناچیز
- مقیاس سیستم: ۸ نود سختافزاری بر پایه پلتفرم Grace Blackwell.
- منابع پردازشی: ۱۶۰ هسته Arm به همراه ۸ گرافیک نسل Blackwell.
- حافظه و شبکه: ۱ ترابایت حافظه فوقسریع LPDDR5X و شبکه 400GbE RDMA.
- مصرف انرژی: کمتر از ۴۳۰ وات در حالت Idle و زیر ۱ کیلووات در فشار کاری کامل.
در این مقاله به بررسی جامع یکی از پروژههای جالب و چالشبرانگیز در حوزه سختافزار هوش مصنوعی میپردازیم؛ پروژهای که توسعهدهندگان آن ماهها برای آمادهسازیاش زمان صرف کردهاند. در ماه فوریه، تیمی از متخصصان موفق شدند هشت دستگاه NVIDIA GB10 را گردآوری کرده و سیستمی را بسازند که در آن زمان بههیچوجه پشتیبانی رسمی نمیشد. در آن برهه، انویدیا تنها از اتصال ۲ نود GB10 از طریق کابل DAC پشتیبانی میکرد و در رویداد GTC 2026 این پشتیبانی به ۴ نود افزایش یافت. با این حال، در این پروژه یک کلاستر ۸ نودی با ۱ ترابایت حافظه، ۱۶۰ هسته پردازشی Arm و سوییچهای شبکه 400GbE با قابلیت RDMA با موفقیت راهاندازی شده است.
هدف اصلی توسعهدهندگان از این کار، اجرای محلی مدل زبانی عظیم Kimi K2.5 بود. در نهایت، نهتنها مدلهای K2.5 و K2.6 روی این کلاستر اجرا شدند، بلکه این پروژه تجربیات ارزشمندی در زمینه شبکهسازی، Tensor Parallel و بهینهسازی کلاسترها ارائه داده است که در این مقاله آنها را زیر ذرهبین آلفاتک قرار میدهیم.

نگاهی اجمالی به سیستم NVIDIA GB10
در حال حاضر هشت تولیدکننده بزرگ شامل Dell, Lenovo, ASUS, Gigabyte, HP, MSI و Acer ماشینهایی بر پایه پلتفرم قدرتمند NVIDIA GB10 توسعه دادهاند.

هر یک از این ماشینها شامل ویژگیهای کلیدی زیر است:
- پردازنده ترکیبی NVIDIA GB10 “Grace Blackwell” مجهز به ۲۰ هسته Arm و گرافیک نسل بلکول.
- ۱۲۸ گیگابایت حافظه مجتمع و فوقسریع LPDDR5X.
- کارت شبکه داخلی NVIDIA ConnectX-7 با پهنای باند 200GbE.
- ۱ تا ۴ ترابایت فضای ذخیرهسازی محلی NVMe.
- اتصالات شبکه 10Gbase-T و وایفای داخلی.
برخلاف مینیپیسیهای معمول، به لطف هستههای قدرتمند Arm، این پلتفرم از توان پردازشی CPU بسیار بالایی نیز برخوردار است. شبکه پرسرعت ConnectX-7 دقیقاً همان عاملی است که در این پروژه به تیم سازنده اجازه داد سیستمها را از یک یا دو نود، تا هشت نود مقیاسپذیری کنند.
شبکهسازی؛ کلید اصلی اتصال کلاستر ۸ نودی
برای اتصال ۸ نود به یکدیگر، استفاده از کابلهای ساده DAC کافی نیست و وجود یک سوییچ شبکه حرفهای الزامی است. از آنجایی که استفاده از سوییچهای پرمصرفی مثل Dell Z9332F-ON با مصرف ۹۰۰ وات در تناقض با هدف این پروژه (ساخت یک کلاستر کممصرف) بود، سازندگان رویکرد دیگری را در پیش گرفتند.

در این معماری از سوییچ MikroTik CRS804 DDQ استفاده شده است. این سوییچ ۴ پورتی 400GbE، امکان بهرهگیری کامل از قابلیت RDMA (برای RoCE) و مقیاسپذیری از طریق کتابخانههای NCCL انویدیا را فراهم میآورد. هر پورت QSFP56-DD در این سوییچ، توانایی مدیریت دو نود GB10 را داراست.


در کنار شبکه 200Gbps، تیم توسعهدهنده وایفای داخلی سیستمها را غیرفعال کرده و از پورتهای 10GbE صرفاً برای مدیریت شبکه استفاده کردهاند. برای این منظور، سوییچهای Cisco Catalyst C1300-12XT-2X و QNAP QSW-M3216R به کار گرفته شدهاند تا تاخیر شبکه برای بارگذاری مدلها به حداقل ممکن برسد.


فضای ذخیرهسازی اشتراکی (NAS) در این پروژه
بر اساس گزارشات این پروژه، خرید سیستمهای GB10 با ظرفیت ۱ ترابایت (به جای نسخههای ۴ ترابایتی) باعث صرفهجویی چشمگیر ۱۰ هزار دلاری در هزینهها شده است. برای جبران این فضا، از یک ذخیرهساز تحت شبکه (NAS) قدرتمند مدل QNAP TS-h1290FX استفاده شده است.


نقش این ذخیرهساز در کلاستر شامل دو بخش اصلی است: ۱) میزبانی تمام مدلهای زبانی حجیم (که اغلب بالای ۵۰۰ گیگابایت فضا نیاز دارند) جهت جلوگیری از پر شدن حافظه محلی نودها. ۲) ایجاد دایرکتوریهای ایزوله برای AI Agentها با قابلیت اسنپشات ZFS تا از هرگونه حذف ناگهانی اطلاعات توسط عاملهای هوش مصنوعی جلوگیری شود.

مراحل کلیدی راهاندازی و پیکربندی سیستم
پیکربندی چنین مجموعهای بسیار فراتر از نصب یک کارت گرافیک ساده است. هرچند کتابخانههای NCCL انویدیا کار را تسهیل کردهاند، اما بر اساس مستندات این پروژه، رعایت اصول زیر برای پایداری سیستم الزامی بوده است:
- اتصال فیزیکی دقیق پورتهای ConnectX-7 و خاموش کردن وایفای در سطح سیستمعامل برای جلوگیری از تداخل ارتباطی.
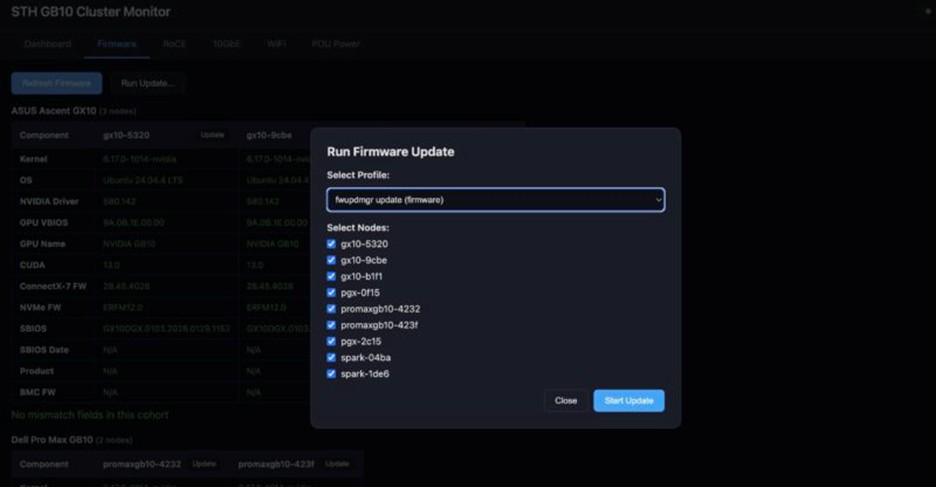
- بهروزرسانی هماهنگ فِرمورها در تمام نودها (وجود کوچکترین تضاد در نسخه فِرمور، عملکرد کلاستر را مختل میکند).
- تنظیمات دقیق سوییچ میکروتیک شامل پیکربندی MTU، PFC و ECN از طریق محیط خط فرمان (CLI).
- تست سرعت شبکه RDMA به صورت دوطرفه برای اطمینان از دریافت سرعتهای بسیار بالاتر از شبکههای استاندارد 10GbE.
- راهاندازی vLLM بهصورت کانتینری و حصول اطمینان از برقراری ارتباط نودها صرفاً بر بستر 200GbE.

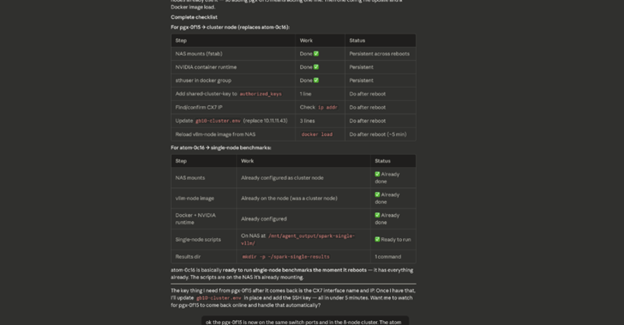
نکته جالب توجه در این پروژه این است که با ابزارهای سال ۲۰۲۶، تمامی مراحل شبکهسازی، تخصیص استوریج و دیپلویمنت به دست عاملهای هوش مصنوعی (مانند Claude Code یا OpenClaw) سپرده شده است؛ اختصاص دادن ۱ ترابایت رم و ۱۶۰ هسته Arm به یک هوش مصنوعی برای پیکربندی خودش، ایدهای جسورانه است که به خوبی عمل کرده است.
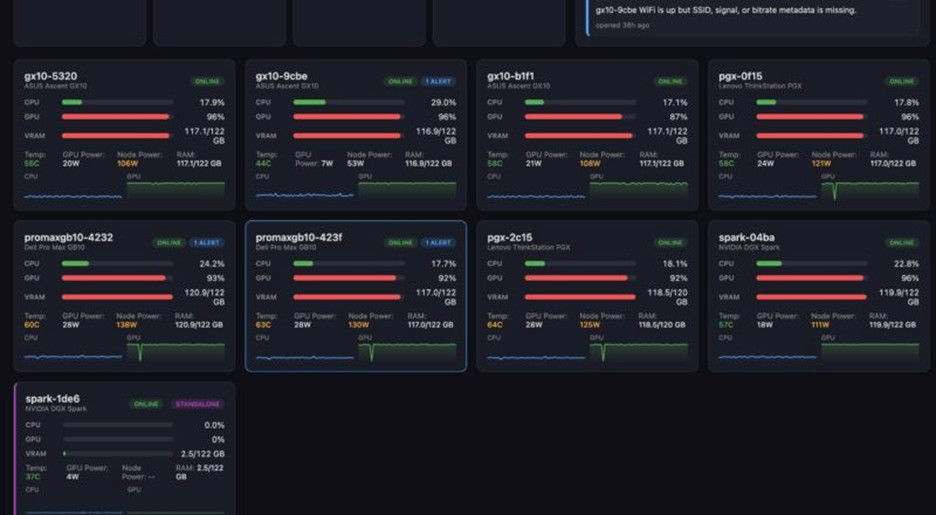
مانیتورینگ کلاستر و مدیریت فِرمورها
در این معماری، یک سیستم مانیتورینگ اختصاصی پیادهسازی شده است که اطلاعات حیاتی زیر را در لحظه رصد میکند:
- وضعیت نودها: میزان درگیری CPU و GPU، اشغال حافظه LPDDR5X، دما و توان مصرفی لحظهای.
- شبکه 200GbE و 10GbE: مانیتورینگ پایداری اتصال RDMA و وضعیت خطاهای پورتها.
- همگامسازی فِرمورها: بررسی مداوم تطابق نسخههای درایور انویدیا و ConnectX-7 در کل شبکه کلاستر.
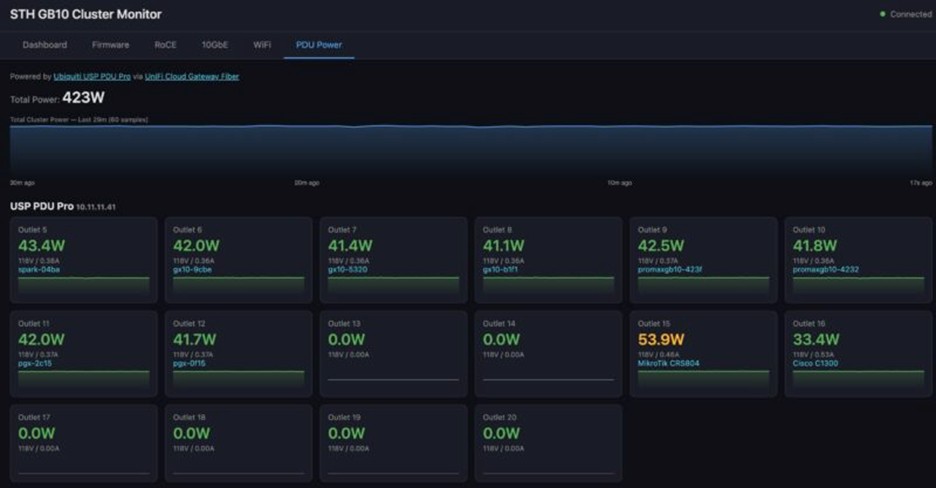
- مدیریت تغذیه: امکان کنترل از راه دور (Remote Power Cycling) برای ریبوت سختافزاری نودها از طریق PDUهای مدیریتپذیر.
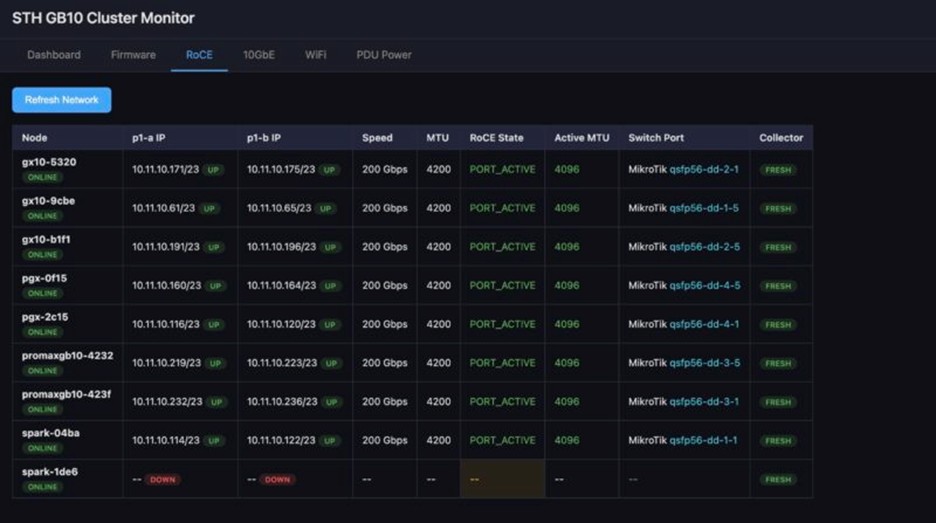
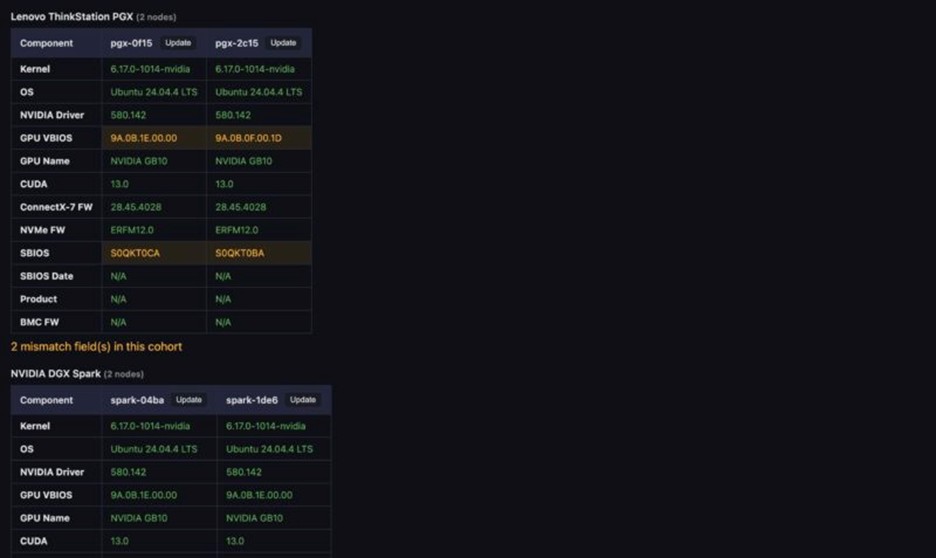
عملکرد، بنچمارکها و بهینهسازیهای اعمال شده
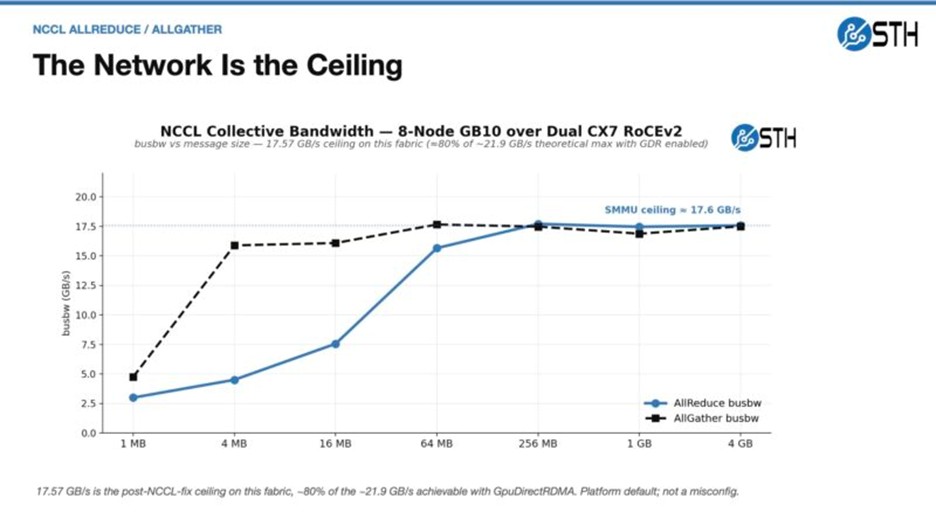
با هدف اجرای مدل Kimi K2.5، تستهای متعددی روی این سیستم صورت گرفته است. توسعهدهندگان در حین بنچمارکها متوجه محدودیتی در پهنای باند شبکه شدند که ریشه آن به معماری SMMU در پلتفرم GB10 بازمیگردد. در این تستها سرعتی معادل ۱۴۰ گیگابیت در ثانیه (به جای 200Gbps اسمی) ثبت شد؛ دلیل این افت، استفاده NCCL از کپیهای مبتنی بر CPU برای دور زدن محدودیتهای DMA-FQ در این معماری است.

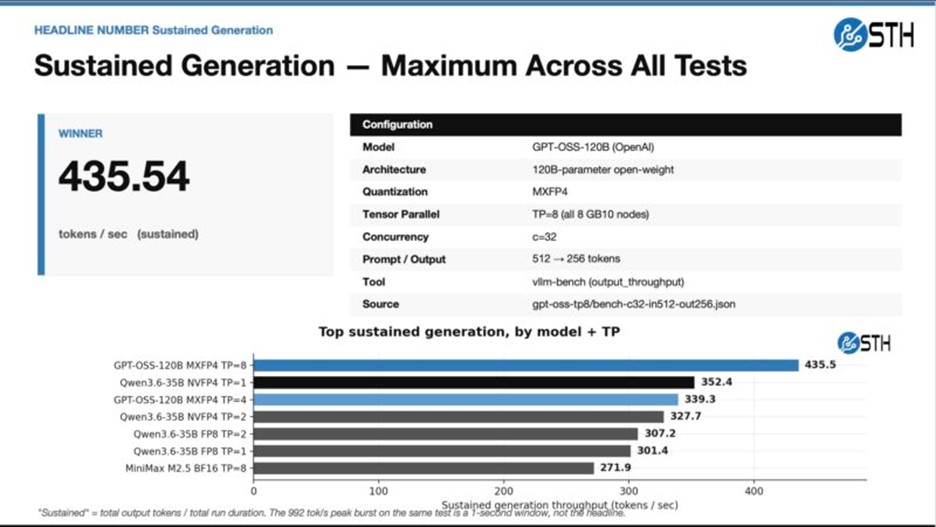
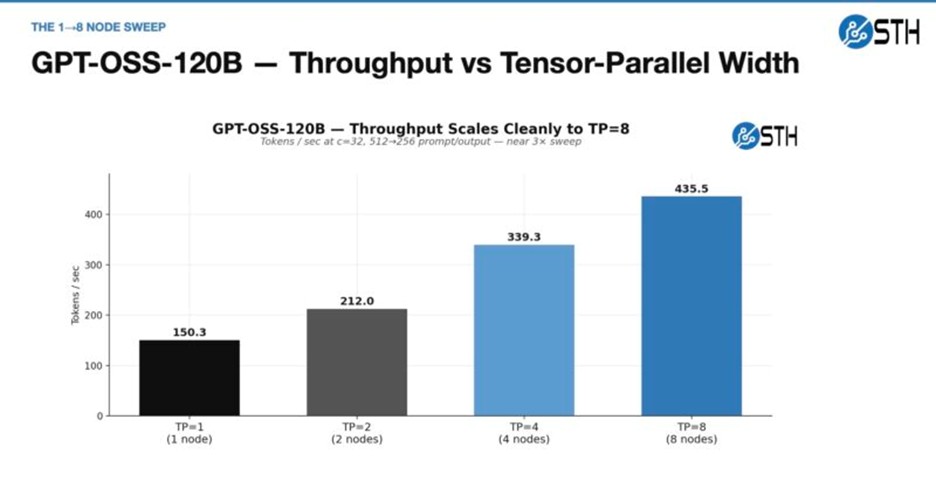
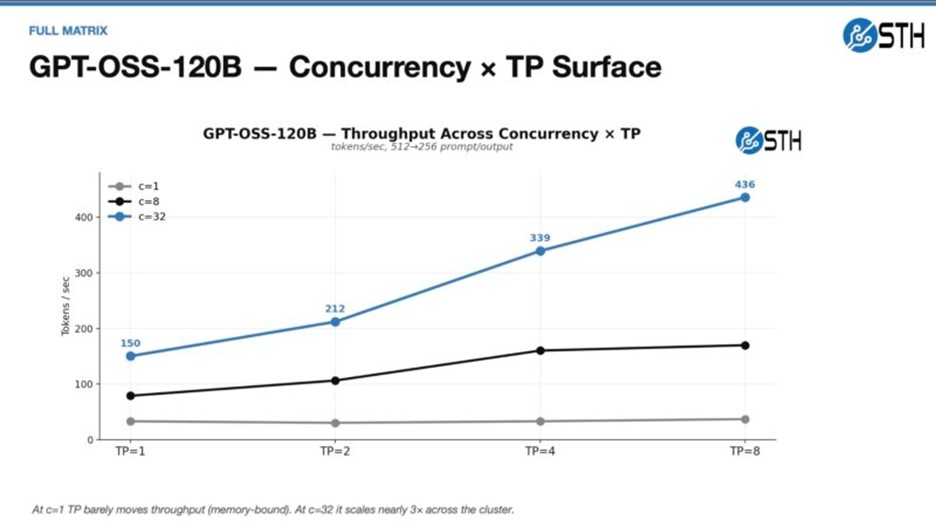
در تست Prefill با مدل عظیم Qwen3.5-397B، استفاده از فرمت NVFP4 به کلاستر کمک کرد تا عملکرد خارقالعادهای از خود نشان دهد. همچنین، در بخش تولید محتوا (Generation) با مدل GPT-OSS-120B نتایج ثبت شده پایداری بالایی را به اثبات رساندند.
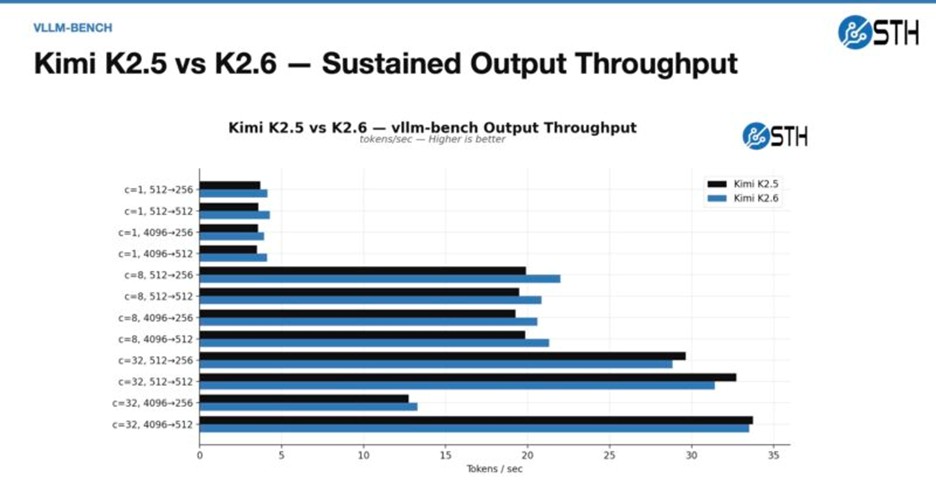
بررسی خروجی مدلهای Kimi K2.5 و K2.6
یافتههای این پروژه نشان میدهد که عملکرد Kimi K2.6 بر روی این کلاستر بهینهتر از نسخه K2.5 بوده است. علیرغم پیشبینیها مبنی بر مشابه بودن عملکرد پردازشی (Decode) در هر دو مدل، در سناریوهایی با میزان همروندی بالا (High Concurrency)، نسخه 2.6 برتری ملموسی از خود نشان داده است.
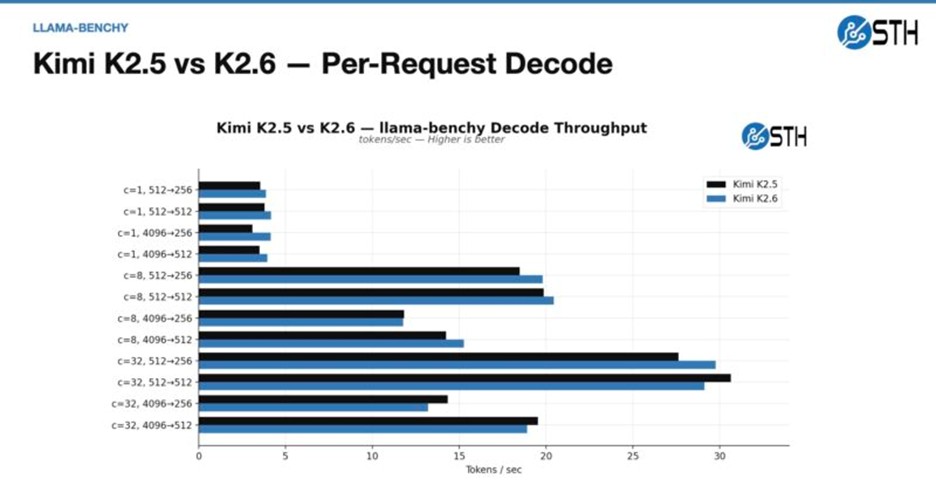

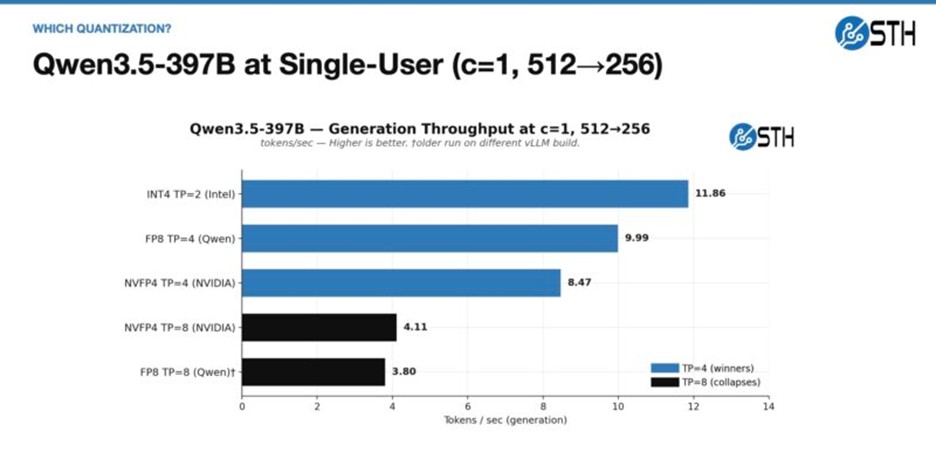
توصیه مهم آلفاتک درباره Tensor Parallel بر اساس نتایج
یکی از مهمترین دستاوردهای بررسی این پروژه، اصلاح یک تصور غلط رایج است: اجرای یک مدل روی ۸ نود لزوماً سریعتر از اجرای آن روی ۱ یا ۴ نود نیست. واقعیت این است که ارتباطات بین نودها در شبکه باعث ایجاد تاخیر (Network Penalty) میشود. نتیجهگیری فنی آلفاتک این است که اگر مدلی در ۴ نود قابل استقرار است، باید روی همان ۴ نود اجرا شود و نیازی به توزیع آن در ۸ نود نیست. مدلهای متراکم زمانی که به صورت محلی یا روی کمترین تعداد نود ممکن اجرا شوند، بالاترین پرفورمنس را ارائه خواهند داد.



مصرف انرژی و میزان نویز سیستم
آمارهای ارائه شده از این کلاستر در بخش مصرف انرژی شگفتانگیز است. کل مجموعه، شامل هشت نود GB10 و سوییچ MikroTik در وضعیت بیکار (Idle) کمتر از ۴۰۰ وات برق مصرف میکند (که با اضافه شدن سوییچ 10GbE این عدد نهایتاً به ۴۳۰ وات میرسد).

تحت شدیدترین فشارهای پردازشی و هنگام اجرای مدل سنگینی چون Kimi K2.5، مصرف برق کل این کلاستر تنها در بازه ۹۰۰ تا ۹۵۰ وات ثبت شده است. این بدان معناست که تامین برق یک ابررایانه هوش مصنوعی تنها با یک پریز استاندارد اداری امکانپذیر شده است! از لحاظ میزان نویز نیز، خود نودها بسیار بیصدا هستند و عمده صدای تولید شده مربوط به فنهای سوییچ شبکه میکروتیک است.

تحلیل تخصصی آلفاتک: چرا این پروژه اهمیت بالایی دارد؟
ممکن است تهیه یک سرور DGX Station یا راهاندازی کلاستری مبتنی بر RTX Pro 6000 قدرت پردازش خام بیشتری فراهم کند، اما معماری کلاستر ۸ نودی GB10 نقاط قوت منحصربهفردی دارد که توجه کارشناسان آلفاتک را به خود جلب کرده است:
- تضمین حریم خصوصی: اجرای محلی و On-Premise مدلهای زبانی عظیم، خطرات امنیتی ناشی از ارسال دادههای حساس به سرویسهای ابری را بهطور کامل از بین میبرد.
- انقلاب در بهرهوری انرژی: مصرف کمتر از ۱ کیلووات باعث میشود این کلاستر بدون نیاز به زیرساختهای پیچیده برق و کولینگ دیتاسنتری، به راحتی در محیطهای آزمایشگاهی و اداری قابل استقرار باشد؛ مزیتی که در سیستمهای چند کیلوواتی رقیب دیده نمیشود.
- بستر ایدهآل برای توسعهدهندگان: این معماری برای سنجش و پروتوتایپینگ AI Agentها در دنیای واقعی بینظیر است. امکان تقسیم کلاستر به دو بخش ۴ نودی مجزا برای تست همزمان چندین مدل، انعطافپذیری بالایی را در اختیار تیمهای تحقیق و توسعه قرار میدهد.
با پیشرفتهای خیرهکننده ابزارهای اتوماسیون مبتنی بر هوش مصنوعی، دیپلویمنت شبکههای پیچیدهای چون RoCE/RDMA دیگر یک چالش غیرممکن نیست. این پروژه به خوبی اثبات میکند که هوش مصنوعی میتواند پیکربندیهای سنگین کلاسترینگ را به طور خودکار انجام داده و این فناوریهای پیشرفته را برای تیمهای کوچکتر نیز دستیافتنی سازد.







