


انقلاب در ریاضیات شتابدهندهها؛ استارتآپ Tensordyne با تراشه ۳ نانومتری Napier و معماری لگاریتمی انویدیا را به چالش کشید
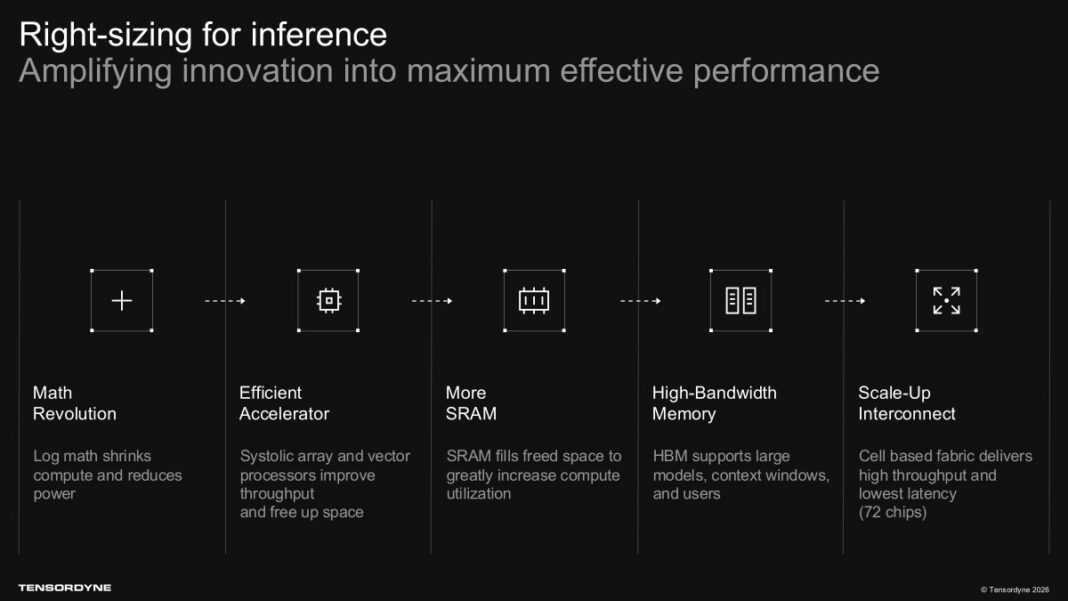
- نوآوری در لایه ریاضیات: تبدیل عملیات پیچیده ضرب به جمع با استفاده از ریاضیات لگاریتمی پسیو جهت بهینهسازی ترانزیستورها و کاهش ابعاد ضربکنندهها.
- مشخصات سیلیکون: تراشه ۳ نانومتری TSMC با ۱۳۸ میلیارد ترانزیستور، مجهز به ۲۵۶ مگابایت حافظه SRAM (پنج برابر بیشتر از انویدیا Blackwell) و ۱۴۴ گیگابایت حافظه HBM3E.
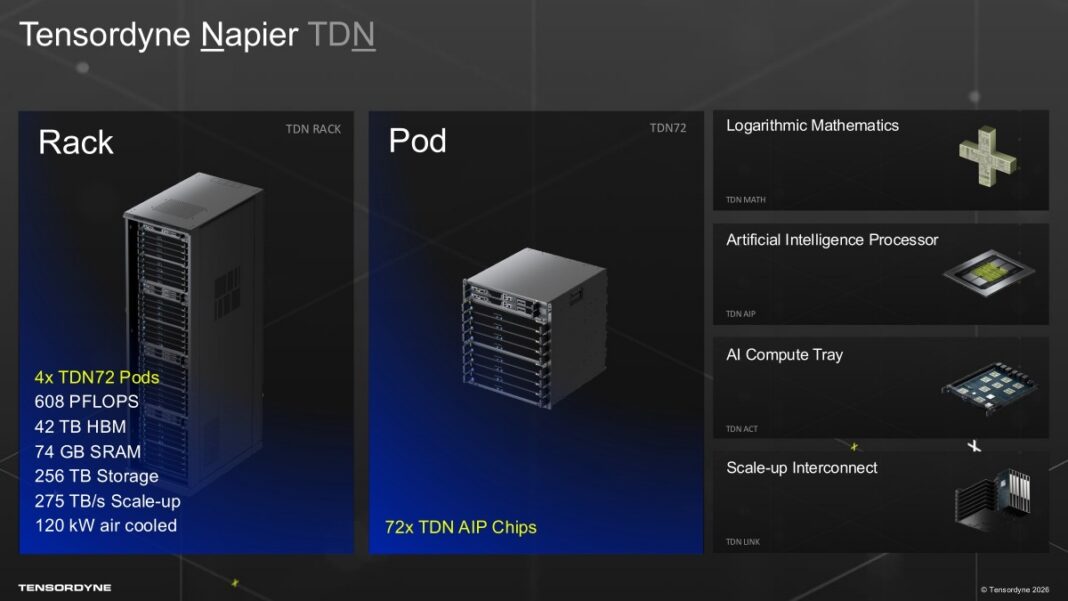
- معماری رکاسکیل (TDN72): کلاستر کارخانهای خنکشونده با هوا (Air-Cooled) با توان مصرفی ۱۲۰ کیلووات برای یک رک شامل ۷۲ نود، با توانایی پردازش مدلهای غولپیکر MoE تا ابعاد ۲۰ تریلیون پارامتر.
- اینترکانکت پرسرعت (TDN Link): پهنای باند ارتباطی ۱ ترابایت بر ثانیه با تاخیر زیر میکروثانیه، بهینهشده برای مدلهای ترکیبی از خبرگان و هوش مصنوعی عاملمحور.
در بازار شلوغ و پررقابت شتابدهندههای هوش مصنوعی، معرفی یک تراشه جدید معمولاً با ادعاهای تکراری درباره افزایش هستهها یا بهینهسازی لیتوگرافی همراه است. اما استارتآپ Tensordyne با رونمایی از پردازنده هوش مصنوعی Napier، رویکردی کاملاً متفاوت و رادیکال را اتخاذ کرده است. این تراشه ۳ نانومتری و پلتفرم استنتاجی رکاسکیل (Rack-scale) همراه آن، بر پایه یک ساختار ریاضیاتی انحصاری یعنی ریاضیات لگاریتمی (Logarithmic Mathematics) بنا شدهاند.
ادعای محوری این شرکت این است که تغییر متدولوژی ریاضی در داخل شتابدهنده میتواند فضای اشغالشده توسط ضربکنندهها (Multiplier Area) را به شدت کاهش داده، ظرفیت حافظه کش روی تراشه (SRAM) را افزایش دهد و در نهایت، اقتصاد محاسبات استنتاجی (Inference Economics) را در سطح رک دگرگون کند. در حال حاضر، تراشه Napier مرحله تپ-اوت (Tape-out) را با موفقیت پشت سر گذاشته و نقشهراه سیستمهای آن برای سال ۲۰۲۷ برنامهریزی شده است. سوال کلیدی برای مدیران زیرساخت فناوری اطلاعات این است که آیا این ادعاهای عملکردی و نرمافزاری در مواجهه با محیطهای ابری و استقرارهای واقعی دوام خواهند آورد یا خیر.

انقلاب ریاضیاتی؛ تبدیل عملیات ضرب به جمع برای بهینهسازی سیلیکون
شرکت Tensordyne پردازنده Napier را به عنوان ابزاری استراتژیک برای حمله همزمان به دو چالش بزرگ هوش مصنوعی، یعنی «سرعت پردازش» و «هزینه استنتاج» معرفی کرده است. به جای تکیه بر منابع سنتی ضرب ماتریسی (Matrix-multiply) که بخش اعظم معماری تراشههای انویدیا و AMD را اشغال میکنند، رویکرد ریاضیات لگاریتمی این شرکت، عملیات پیچیده و سنگین ضرب را به عملیات سادهتر و سریعتر جمع (Additions) تبدیل میکند.
از منظر مهندسی سختافزار، جمعکنندهها (Adders) به مراتب کوچکتر از ضربکنندهها هستند و توان مصرفی بسیار کمتری دارند. بنابراین، با کوچک شدن فوتپرینت واحدهای محاسباتی ریاضی، فضای آزادشده روی سطح سیلیکون به حافظه کش پرسرعت SRAM اختصاص مییابد که تعادل سیستم را بهبود میبخشد. این شرکت با هدف تجاریسازی این فناوری، یک اکوسیستم کلاسترینگ و معماری رکاسکیل اختصاصی را فراتر از عرضه یک تراشه منفرد معرفی کرده است.

کالبدشکافی سیلیکون Napier؛ ۵ برابر SRAM بیشتر نسبت به انویدیا Blackwell
تراشه Napier یک پردازنده ۳ نانومتری ساخته شده در کارخانههای TSMC است که میزبان ۱۳۸ میلیارد ترانزیستور است. این سیلیکون توانایی ارائه ۲.۱ پتافلاپ توان محاسباتی به ازای هر دای (Die) را دارد و از یک هسته شتابدهنده با فرکانس ۱.۳۳ گیگاهرتز در کنار یک پردازنده مرکزی (CPU) با فرکانس ۱.۵ گیگاهرتز بهره میبرد. ساختار حافظه هر تراشه شامل ۲۵۶ مگابایت حافظه کش SRAM و ۱۴۴ گیگابایت حافظه فوقسریع HBM3E است.
یکی از هیجانانگیزترین ادعاهای فنی Tensordyne این است که پردازنده Napier به ازای هر تراشه، پنج برابر حافظه SRAM بیشتری نسبت به معماری انویدیا Blackwell ارائه میدهد. در صورتی که این ادعا در بارهای کاری واقعی دیتاسنتر اثبات شود، این حجم عظیم از SRAM به سیستم اجازه میدهد تا دادههای حیاتی را در نزدیکترین فاصله ممکن به بافت محاسباتی (Compute Fabric) حفظ کند و جریمههای سنگین ناشی از تاخیر جابجایی دادهها (Data Movement Penalty) را در کلاستر به شدت کاهش دهد.

پلتفرم رکاسکیل TDN72؛ بهینهسازی توکن به ازای هر مگاوات
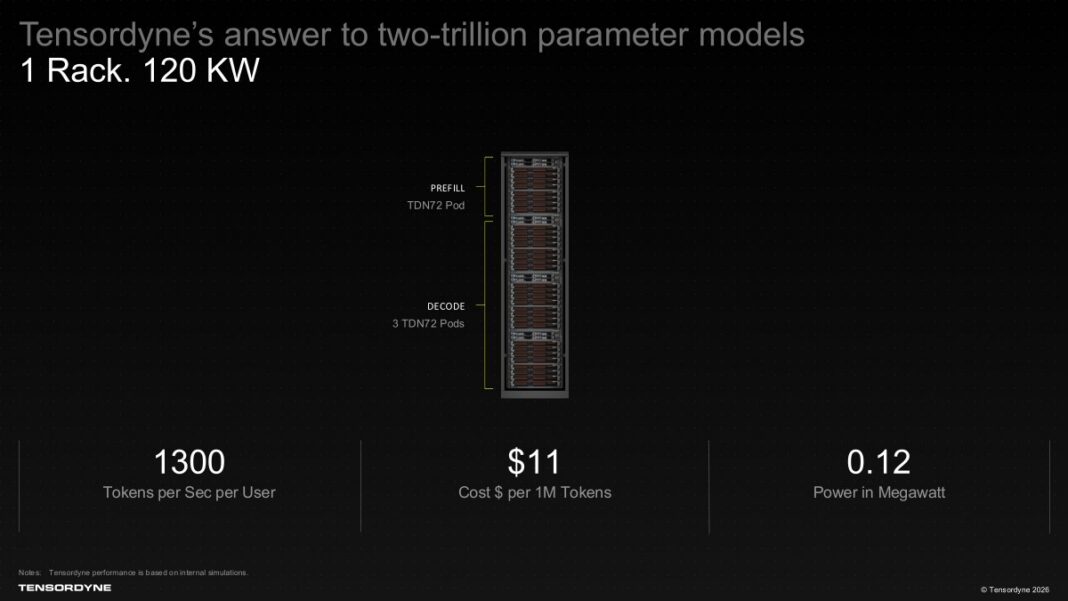
در پارادایم فعلی زیرساختهای هوش مصنوعی، بحثها دیگر صرفاً به توان نامی پیکِ TOPS یا FLOPS محدود نمیشود. استنتاج با کانتکستهای طولانی (Long-context Inference)، جریانهای کاری عاملمحور (Agentic Workflows) و مدلهای ترکیبی از خبرگان (MoE)، همگی به شدت تحت تنگنای ظرفیت حافظه، اینترکانکت، توان مصرفی رک و سیستمهای سرمایهشناسی قرار دارند. استدلال Tensordyne این است که طراحی متوازن تراشه و رک میتواند تعداد توکنهای خروجی بیشتری را به ازای هر رک و به ازای هر مگاوات مصرف انرژی (Tokens per megawatt) تحویل سازمانها دهد.
این شرکت رک اختصاصی خود موسوم به TDN72 را با کلاسترهای چندرکی بزرگ بازار برای پردازش مدلهای ۲ تریلیون پارامتری GPT MoE مقایسه کرده است. طبق ادعای این شرکت، تنها یک رک ۱۲۰ کیلوواتی TDN72 میتواند به سرعت ۱۳۰۰ توکن بر ثانیه به ازای هر کاربر دست یابد؛ در حالی که پلتفرمهای انویدیا و Groq برای ثبت همین رکورد به ۹ رک مجزا و توان مصرفی ۱.۵ مگاوات نیاز دارند و کلاسترهای آمازون (AWS) و Cerebras نیز نیازمند ۱۴ رک و توان ۸۰۰ کیلووات هستند.

یک سیستم کامل TDN72 بر پایه ۷۲ نود پردازشی، ۶۸ پتافلاپ توان محاسباتی کل و ۴۲ ترابایت حافظه اختصاصی HBM مهندسی شده است. این ظرفیت خیرهکننده، مدلهایی با ابعاد ۱۰ تا ۲۰ تریلیون پارامتر را هدف قرار میدهد؛ جایی که ردپای حافظه و هدایت هوشمند کارشناسان (Expert Routing) به بزرگترین چالشهای مهندسی زیرساخت تبدیل میشوند.
اینترکانکت TDN Link و توپولوژی بدون محدودیت برای مدلهای عاملمحور
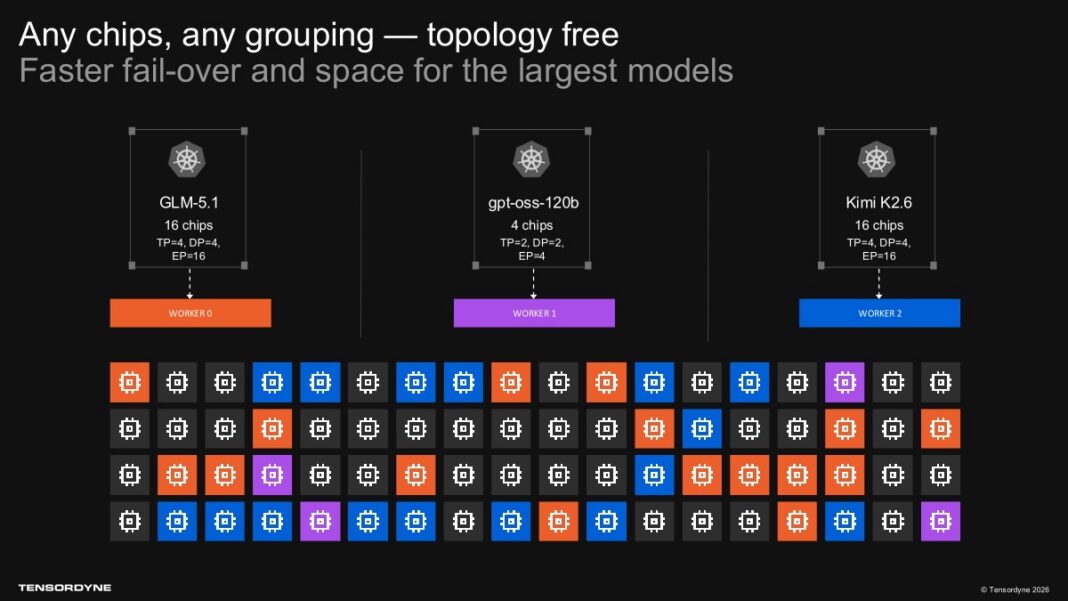
بخش بسیار مهمی از معماری رکاسکیل Tensordyne، ساختار اینترکانکت اختصاصی آن به نام TDN Link است. این شبکه ارتباطی قادر است تاخیر ارتباط چیپبهچیپ را به زیر میکروثانیه کاهش داده و پهنای باند ۱ ترابایت بر ثانیه را در سراسر سیستم ۷۲ تراشهای برقرار کند.

برای مدلهای MoE و بارهای کاری هوش مصنوعی عاملمحور، لایه ارتباطی نقشی حیاتیتر از خود شتابدهنده ایفا میکند؛ زیرا فرآیند فعالسازی نودها و جابجایی ترافیک میان کاربران، تاخیرهای شبکه را به شدت به چالش میکشد. بر خلاف ستون فقرات NVL72 انویدیا، راهکار Tensordyne بیشتر شبیه به یک سوییچ شبکه شاسیکلاس کلاسیک عمل میکند.

این اینترکانکت انعطافپذیری فوقالعادهای را در لایه توپولوژی ارائه میدهد. فناوری Tensordyne اجازه میدهد که هر گروه از تراشهها به صورت پویا برای یک بار کاری خاص دستهبندی شوند؛ قابلیتی که در صورت پایداری نرمافزار، فرآیند تغییر وضعیت خودکار در زمان بروز خطا (Topology-free Failover) و بازنشانی مدلها را کاملاً شفاف و بدون قطعی میکند.
اکوسیستم نرمافزاری؛ عبور از سد انحصار CUDA انویدیا
لایه نرمافزاری همواره پاشنه آشیل استارتآپهای سختافزاری بوده است. انحصار عمیق اکوسیستم CUDA انویدیا، سد محکمی در برابر ورود پلتفرمهای جایگزین است. Tensordyne برای حل این چالش، از یک هاب مدل میزبانیشده در هازینگفیس (Hugging Face) به همراه اسدیکی (SDK) اختصاصی خود رونمایی کرده است.
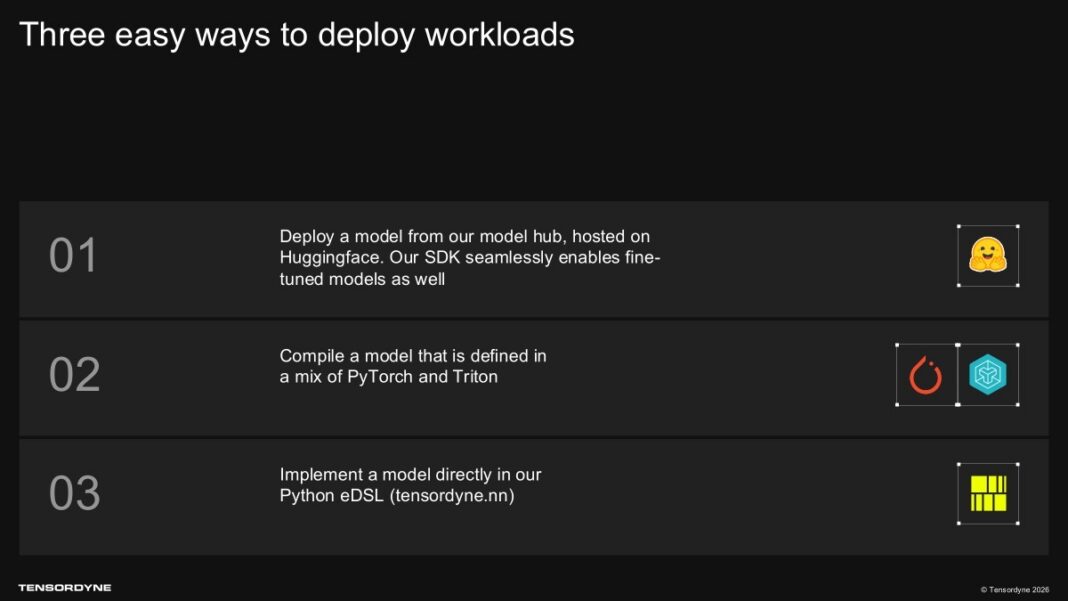
این ساختار نرمافزاری امکان کامپایل مستقیم مدلهای توسعهیافته با PyTorch و فریمورک Triton را فراهم میکند و یک زبان بومی پایتون اختصاصی (eDSL) به نام tensordyne.nn را در اختیار توسعهدهندگان قرار میدهد تا فرآیند پورت کردن مدلها به لایه محاسبات لگاریتمی تسهیل شود.
جدول مشخصات فنی رسمی تراشه و کلاستر رکاسکیل Tensordyne
| کامپوننت سختافزاری | مشخصات فنی تراشه Napier (تک دای) | مشخصات کلاستر کامل لایه رک (TDN72 Pod) |
|---|---|---|
| لیتوگرافی و فرآیند ساخت | ۳ نانومتری شرکت TSMC (از طریق Broadcom) | معماری مرجع رکاسکیل کارخانهای یکپارچه |
| تعداد ترانزیستورها | ۱۳۸ میلیارد ترانزیستور | پیکربندی شده در قالب ۷۲ نود پردازشی مستقل |
| توان محاسباتی (Compute) | ۲.۱ پتافلاپ (فرکانس شتابدهنده ۱.۳۳ گیگاهرتز) | ۶۸ پتافلاپ توان پردازش کل کلاستر |
| فرکانس پردازنده مرکزی (CPU) | ۱.۵ گیگاهرتز (هستههای بومی میزبان) | پشتیبانی شده توسط پردازندههای میزبان Intel Xeon |
| ظرفیت حافظه روی تراشه (SRAM) | ۲۵۶ مگابایت (۵ برابر ظرفیت انویدیا بلکول) | توزیعشده در سراسر بستر شتابدهندهها |
| ظرفیت حافظه پهنباند (HBM) | ۱۴۴ گیگابایت حافظه پیشرفته HBM3E | ۴۲ ترابایت حافظه کل کلاستر رکاسکیل |
| مکانیزم خنکسازی (Cooling) | طراحی بهینه پسیو ساختار داخلی سینی | ۱۰۰٪ خنکشونده با هوا (Air-Cooled) در توان ۱۲۰ کیلووات |
| ارتباطات ورودی/خروجی (I/O) | درگاه ارتباطی بومی پرسرعت TDN Link | پشتیبانی از پورتهای دوگانه شبکه 2x 200GbE |
در سطح واحد فیزیکی، Tensordyne تعداد ۹ تراشه Napier را درون یک سینی پردازشی ۱U (نظام تجاری AI Compute Tray) همراه با ۱.۳ ترابایت حافظه HBM3E، ۸ ترابایت فضای ذخیرهسازی داخلی و پردازندههای میزبان اینتل زئون بستهبندی کرده است. چهار سینی یک پاد را تشکیل میدهند و چهار پاد درون یک رک استاندارد ۵۲RU مستقر میشوند؛ سیستمی که به طور کامل با هوا خنک میشود (Air-cooled) و نیازی به مقاومسازی پیچیده دیتاسنترها با سیستمهای مایع ندارد.

تحلیل اختصاصی آلفاتک: کارآمدی فرضیه لگاریتمی در مواجهه با واقعیت دیتاسنتر
پلتفرم Tensordyne Napier بدون شک یکی از اصیلترین طرحهای سختافزاری معرفیشده در سال ۲۰۲۶ است؛ زیرا به جای کپیبرداری صِرف از معماری شتابدهندههای انویدیا و رقابت بر سر قیمت، بنیانهای ریاضی محاسبات را تغییر داده است. تبدیل ضرب به جمع روی کاغذ یک ایده نبوغآمیز است که اجازه میدهد بخش عمدهای از ترانزیستورها به جای واحدهای منطقی ریاضی (ALUs)، به بافر حافظه (SRAM) تخصیص یابند و ادعای وجود ۵ برابر کش بیشتر نسبت به Blackwell را محقق کنند. این ویژگی، گلوگاه استنتاج در مدلهای طویلکانکتست و عاملمحور را هدف قرار میدهد.
با این وجود، به عنوان رسانهای راهبردی برای مدیران دیتاسنتر، باید جنبههای پنهان این معماری را به چالش بکشیم. اولاً، تغییر فرمت محاسباتی به لگاریتمی، فرآیند پورت کردن مدلها را با چالشهای احتمالی افت دقت (Accuracy Loss) مواجه میکند و فریمورکهای کامپایلر Triton یا eDSL اختصاصی شرکت باید در محیط پروداکشن کارایی خود را اثبات کنند. ثانیاً، مهندسی یک رک با توان مصرفی ۱۲۰ کیلووات منحصراً بر پایه خنککننده بادی (Air-Cooled)، یک چالش حرارتی بسیار پرریسک است؛ چرا که دیتاسنترهای مدرن امروزی برای توانهای بالای ۵۰ کیلووات به ناچار به سمت خنککنندههای مایع (Liquid Cooling) کوچ کردهاند. همچنین، استفاده از درگاه ارتباطی 2x 200GbE نشان میدهد که این سیستم هنوز به معماری PCIe Gen6 ارتقا نیافته و از پهنای باند ۸۰۰ گیگابیتی عقب مانده است. با تمام این اوصاف، شراکت استراتژیک با برندهای بزرگی چون HPE و Juniper نشان میدهد که زنجیره تامین و ساختار شاسی این محصول بسیار پایدار طراحی شده و در صورت موفقیت برنامههای بتا در سهماهه نخست ۲۰۲۷، Tensordyne میتواند به یک کارت تاریک (Wildcard) فوقالعاده سودآور در دیتاسنترهای آینده تبدیل شود.







